

Take a look at our newest merchandise
![[Windows 11 Pro]HP 15 15.6″ FHD Business Laptop Computer, Quad Core Intel i5-1135G7 (Beats i7-1065G7), 16GB RAM, 512GB PCIe SSD, Numeric Keypad, Wi-Fi 6, Bluetooth 4.2, Type-C, Webcam, HDMI, w/Battery](https://m.media-amazon.com/images/I/71LYTzK2A8L._AC_SL1500_.jpg)



After months of rumors, hypothesis and leaks, NVIDIA CEO Jensen Huang formally unveiled the GeForce RTX 50 sequence based mostly on the RTX Blackwell graphics structure, throughout a mega-keynote handle on the Michelob Extremely Area in Las Vegas throughout CES 2025. For normal readers, the preliminary bulletins weren’t a shock, however a number of the inner-workings and new options in RTX Blackwell that Jensen revealed left many in attendance (and viewing on-line) slack-jawed, for a number of causes.
The RTX Blackwell graphics structure on the basis of the GeForce RTX 50 sequence takes all the pieces from the corporate’s earlier gen Ada structure – which powers the RTX 40 sequence – and cranks it as much as 11. RTX Blackwell additionally introduces the idea of neural rendering, which is able to probably mark a paradigm shift in the way in which PC video games are rendered sooner or later.
For sure, there’s quite a bit to get to. However earlier than we dive in, we have to level you to some earlier protection. You may watch NVIDIA’s CES Keynote right here for particulars straight from the horse’s mouth, and take a look at the playing cards and the GeForce RTX 5090’s tiny PCB too. We will save the deep dive on the precise {hardware} for our upcoming opinions, and concentrate on the precise RTX Blackwell structure and what it allows right here…
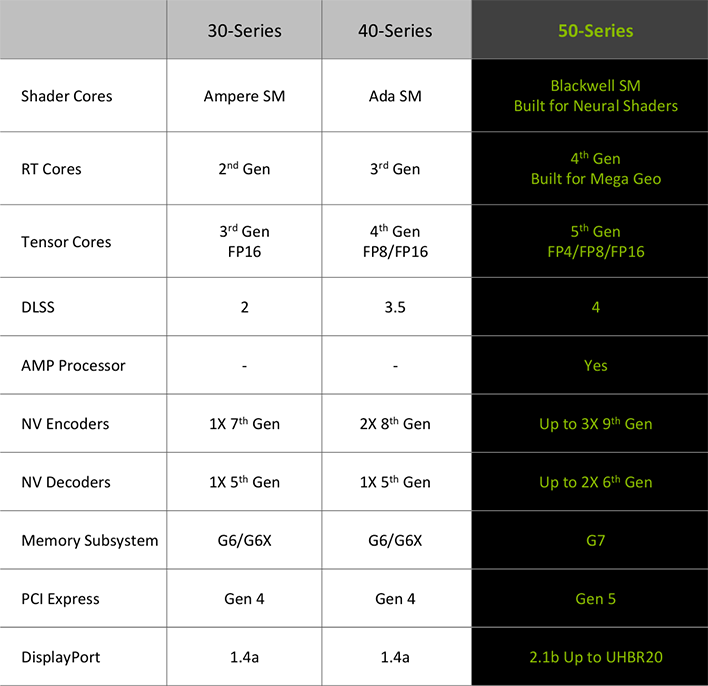
We’re going to dive deeper on the pages forward, however this fast abstract evaluating the previous couple of GeForce generations lays a lot of the groundwork. The GeForce RTX 50 sequence options up to date shader cores with help for neural shaders, along with 4th gen RT (ray tracing) cores and fifth gen Tensor cores, which add help for FP4. DLSS 4 debuts with the RTX 50 sequence, a brand new AI Administration – or AMP – processor is built-in into RTX Blackwell GPUs, and the media engine has been beefed-up with extra, extra succesful encoders and decoders. The RTX 50 sequence additionally incorporates a native PCIe gen 5 interface, help for DisplayPort 2.1b (as much as UHBR20), and GPUs are fed by the most recent excessive velocity GDDR7 reminiscence.
Nearly each facet of the RTX 50 sequence is upgraded over earlier generations, which ends up in vital efficiency uplifts in nearly each kind of workload, from generative AI, to media transcoding, rasterization, and all the pieces in between.

NVIDIA RTX Blackwell Structure Overview
NVIDIA made adjustments and additions to the entire varied cores and IP employed within the GeForce RTX 50 sequence. The shader cores, RT cores, and Tensor cores are all achieve new options and capabilities.
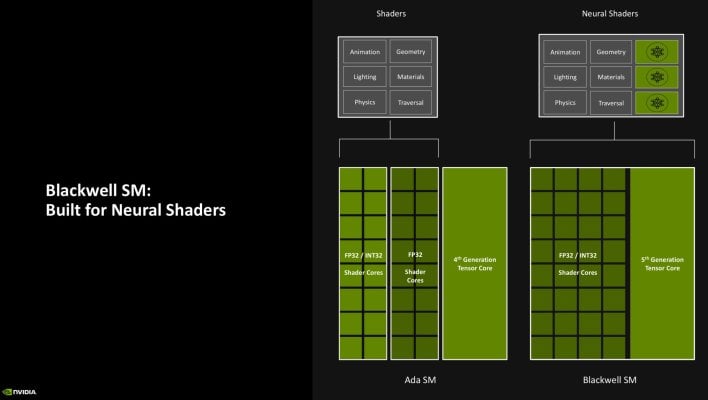
Beginning with the shader cores, NVIDIA enabled full FP32 and INT32 help in the entire shader cores in RTX Blackwell. Within the earlier era Ada graphics structure, half of the shaders in every SM supported FP32 / INT32, whereas the opposite half solely supported FP32. This successfully doubles the INT32 bandwidth. Shader Execution Reordering, or SER, throughput within the SM has additionally doubled in Blackwell.
Neural shaders additionally debut within the RTX 50 sequence. Beforehand, it wasn’t doable to entry the tensor cores by a compute shader in a graphics API. For the RTX 50 sequence, nonetheless, NVIDIA has labored with Microsoft to create one thing referred to as Cooperative Vectors inside DirectX, which unlocks the tensor cores and offers builders the flexibility to run AI fashions on the tensor cores, in recreation. Extra on what that allows shortly.
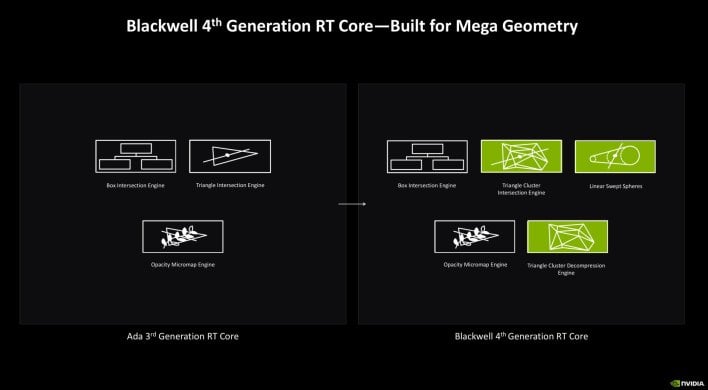
RTX Blackwell’s RT cores have additionally been considerably redesigned. The characteristic related Field Intersection and Opacity Micromap engines to the previous-gen Ada structure, however the Triangle Intersection engine current in Blackwell has been upgraded to what NVIDIA calls a Triangle Cluster Intersection engine, and Triangle Cluster Compression and help for Linear Swept Spheres have been added. The brand new capabilities within the RT cores enabled what NVIDIA calls Mega Geometry.
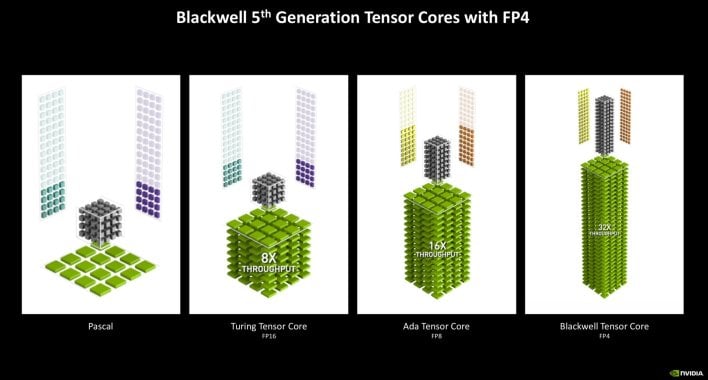
The Tensor cores in RTX Blackwell achieve help for FP4, over and above the FP8 and FP16 help in Ada. Help for FP4 successfully doubles the throughput over FP8, whereas concurrently decreasing reminiscence necessities for a specific mannequin. FP4 additionally technically leads to decreased precision versus FP8 or FP16, however by optimally quantizing fashions for the info kind and structure, the impression in lots of shopper use circumstances needs to be negligible.
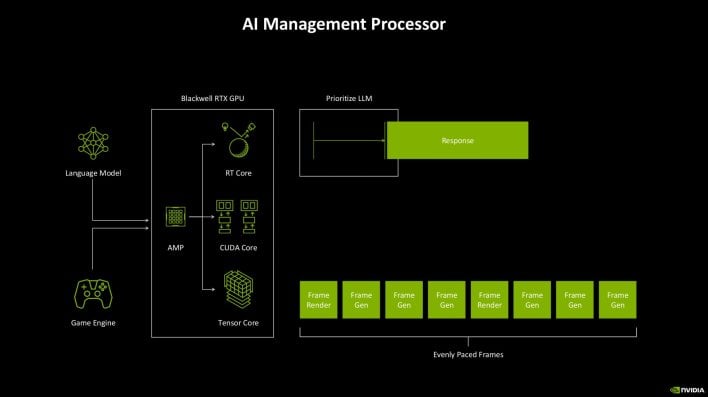
To assist the GeForce RTX 50 sequence higher handle the various AI workloads that might be run on the GPUs alongside conventional recreation engine code, NVIDIA has additionally integrated an AI Administration Processor, or AMP, into the design. AMP is a programmable processor that sits on the entrance of the GPU that may work together carefully with the entire totally different cores. AMP evaluates rendering standards to optimally dispatch and schedule AI and graphics workloads throughout the assorted cores.
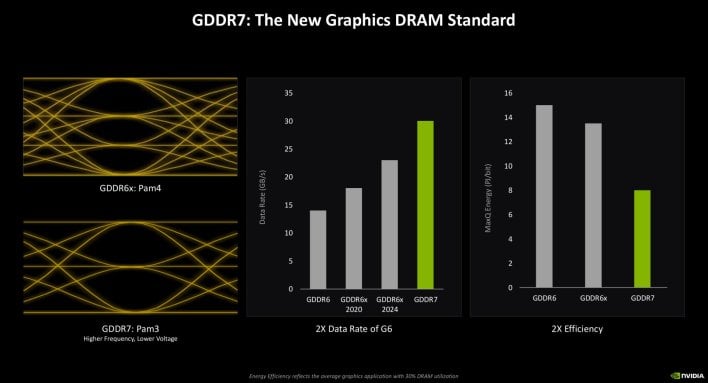
To maintain the GPUs fed with information, NVIDIA is utilizing the most recent GDDR7 reminiscence on the GeForce RTX 50 sequence. GDD7 presents double the info charge of GDDR6 (not 6X), with considerably higher effectivity. That interprets to increased reminiscence bandwidth, and decreased power consumption. The highest finish GeForce RTX 5090 will supply as much as 1.8TB/s of peak reminiscence bandwidth, which is about 80% increased than the RTX 4090.
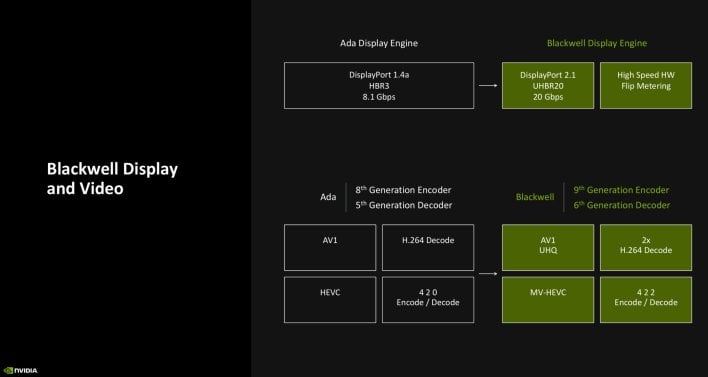
The show and media engines within the RTX 50 sequence have additionally been upgraded versus Ada. The RTX 50 sequence help DisplayPort 2.1 with a UHBR20 information charge of as much as 20Gbps, to allow excessive refresh charges at ultra-high resolutions, with HDR visuals. The RTX 50 sequence additionally options high-performance, {hardware} based mostly Flip Metering, which shifts the body pacing logic to the show engine, to permit the GPU to exactly handle show timing and precisely tempo frames at excessive framerates and when multi body era is used.
RTX 50 Sequence Max-Q Energy Administration
NVIDIA’s objective with the RTX 50 sequence was to extract the utmost quantity of efficiency doable inside a given platform’s energy funds. Like earlier gen chips, when components or the entire GPU are idle, they shortly enter into deeper energy states, or shut off altogether. However NVIDIA enhanced Blackwell’s capabilities on this regard too.

RTX 50 sequence GPUs now help clock, energy and rail gating, and NVIDIA additionally improved the flexibility to dynamically modify frequencies and voltages.
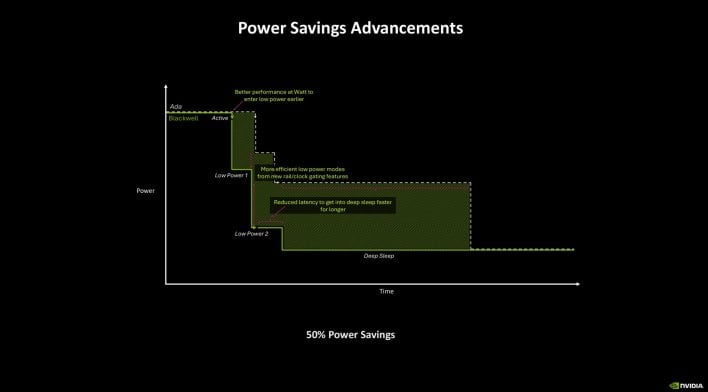
The effectivity optimization begins with clock gating, but when total engines go idle, the logic and SRAMS can benefit from progressively deeper energy states, till getting into the deepest sleep states, or be shut down altogether. A second energy rail for the GPUs has additionally been added and every might be gated as crucial. NVIDIA claims that rail gating particularly helps battery life on the cell variants.
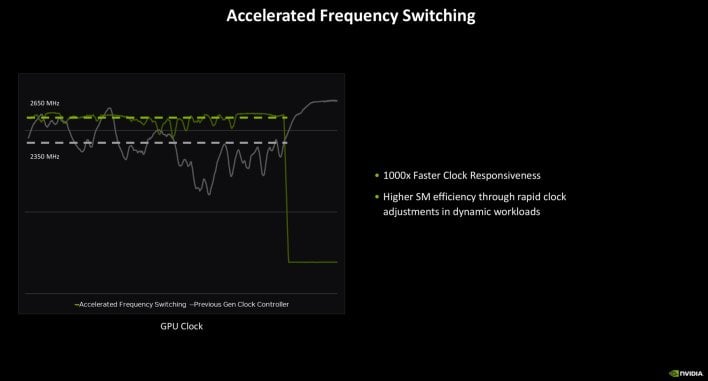
None of that’s actually new, however the RTX 50 sequence can enter deeper energy states and exit them extra shortly than Ada. The truth is, NVIDIA claims Blackwell reduces the time to enter a deep sleep by an element of 10. The brand new GPUs additionally supply accelerated frequency switching, and responsiveness has reportedly been improved by an element of 1000. With The RTX 50 sequence, frequencies might be adjusted with a single body based mostly on the workload, which helps extract most effectivity inside the SMs.
Introducing RTX Neural Rendering
As we talked about earlier, RTX Blackwell additionally introduces the idea of neural rendering and what the corporate calls the “NVIDIA RTX Equipment”. The NVIDIA RTX Equipment is principally an umbrella time period for RTX Neural Shaders, Hair and Pores and skin, RTX Mega Geometry, DLSS 4, Reflex 2, and RTX Remix – which is nearly to hit its 1 yr anniversary.
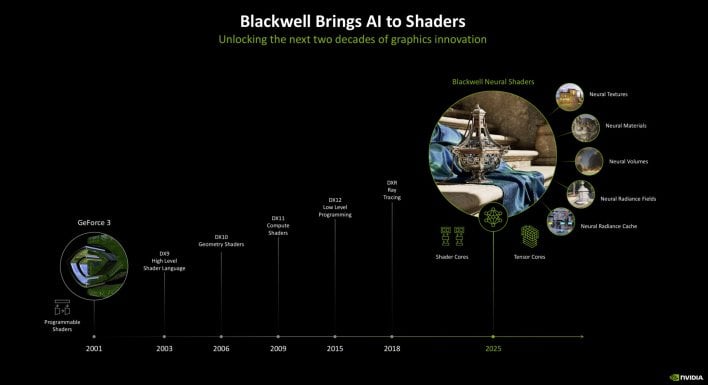
Observe as you’re digesting many of those new applied sciences, that they’re being enabled for builders now, however will arrive in precise video games at varied factors sooner or later, aside from DLSS 4, which might be enabled on day 0 in roughly 75 titles.

RTX Neural Supplies permits recreation builders and artists to create increased high quality, extra lifelike supplies that require fewer reminiscence assets. RTX Neural Supplies takes the shader code and the collective of layers (textures, and so forth.) for a mannequin, builds them out, after which makes use of AI to compresses them at as much as a 7:1 compression ratio, which is considerably higher than conventional block compression strategies. Materials processing can also be as much as 5x quicker than earlier generations. In a single instance proven by NVIDIA, customary supplies required about 47MB of reminiscence, however with RTX Neural Materials the reminiscence requirement was introduced all the way down to 16MB, with higher visible constancy.

Subsequent up is RTX Neural Radiance Cache. RTX Neural Radiance Cache is actually an AI-based method to precisely rending oblique gentle in a scene. It really works by doing coaching in run time utilizing the GPU to create a mannequin in actual time, after which caching the lighting within the scene geospatially. When you play, the small neural networks are coaching on the sport information. What this does is enable only one lookup into the cache to deal with many gentle bounces. It successfully traces the ray path at a shorter distance and lets the AI infer the remaining. RTX Neural Radiance Cache is at present obtainable within the RTX International Illumination SDK, and might be obtainable in Portal with RTX, and is coming to RTX Remix in a couple of months.
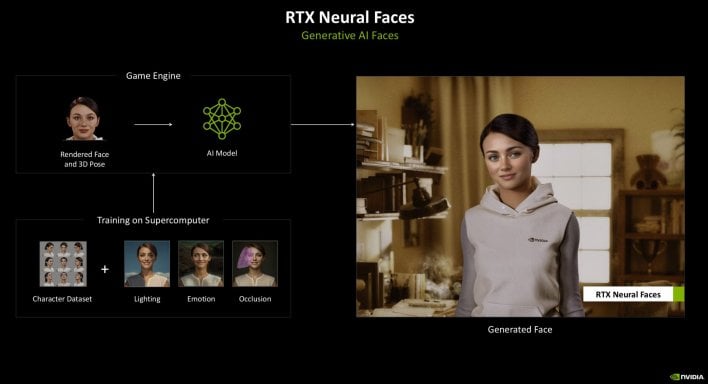
NVIDIA additionally launched RTX Neural Faces, that are high-quality, generative AI faces. RTX Neural Faces takes a regular 3D face and replaces it in actual time with a extra photo-real AI generated face. The demo proven was of considerably increased high quality than the historically rendered face.
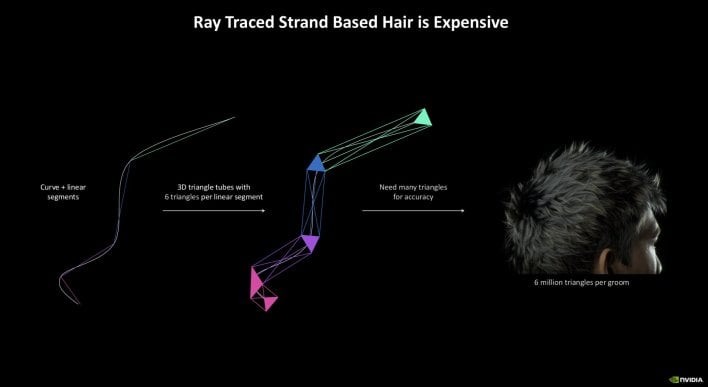
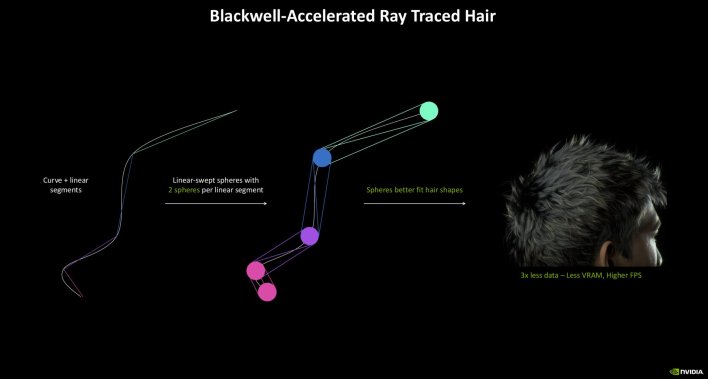
Additionally coming with RTX Blackwell is accelerated Ray Traced Strand Primarily based Hair. Ray tracing hair is computationally heavy, as a consequence of the entire geometry / triangles required for every strand. Blackwell, nonetheless, can ray hint hair utilizing linear swept spheres. Solely two spheres are required per line phase of hair, which is extra concise (as much as 3x much less information) in how it’s saved within the BVH (bounding quantity hierarchy).
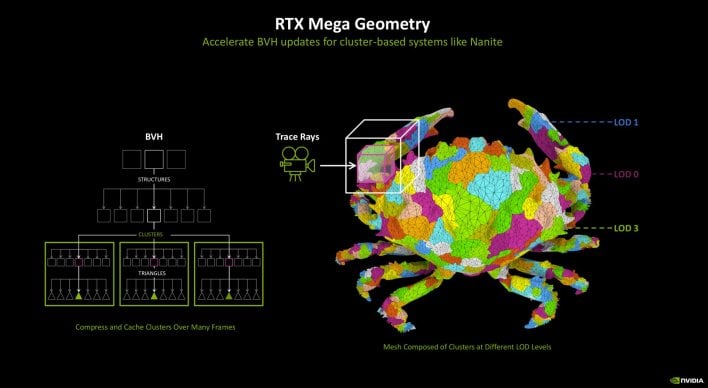
Which brings us to RTX Mega Geometry. RTX Mega Geometry accelerates BVH updates for cluster-based programs like Unreal Engine 5’s Nanite. This offers builders the flexibility to make use of a lot increased decision meshes inside ray traced scenes and eliminates the necessity for proxy meshes, which don’t seize almost the quantity of geometry.
RTX Blackwell Introduces DLSS 4 And Multi Body Era
DLSS can also be getting a whole overhaul with the introduction of the RTX 50 sequence. DLSS 4 introduces multi body era to additional increase framerates and strikes to a transformer AI mannequin to enhance picture high quality and visible constancy.
Transformer fashions might be skilled on a lot bigger information units and infer rather more information from the coaching. Transformers require roughly 4x as a lot compute as earlier DLSS fashions, however finally enable NVIDIA (and finish customers) to raised tweak and modify the tradeoffs between smoothness, framerate and picture high quality that include utilizing a expertise like DLSS. Earlier generations of DLSS used convolutional neural networks (CNN), which produced good outcomes, however might typically end in flickering, shimmering and different artifacts, like ghosting. Many artifacts seen with earlier variations of DLSS are mounted with this new transformer mannequin method.
The “smarter” transformer mannequin additionally enhances tremendous decision, by having the ability to get well and deduce extra particulars, and finally producing a greater upscaled picture.
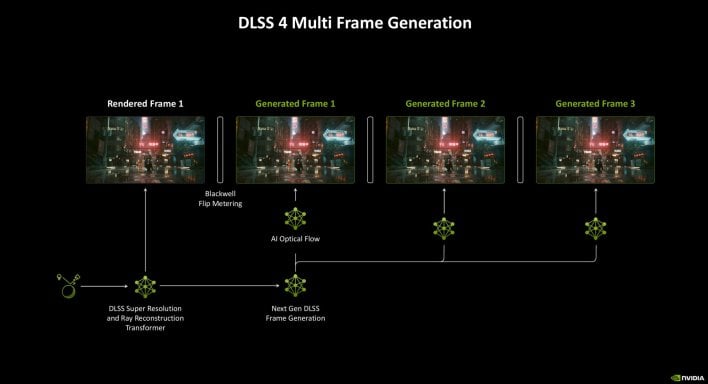
DLSS 4, when utilizing multi body era, might be operating 5 AI fashions per body – the SR and Ray Reconstruction mannequin, the Body-Gen mannequin, and smaller fashions evaluating pairs of rendered frames. The top result’s that 15 out of each 16 pixels you see when multi body gen is enabled are generated by AI.
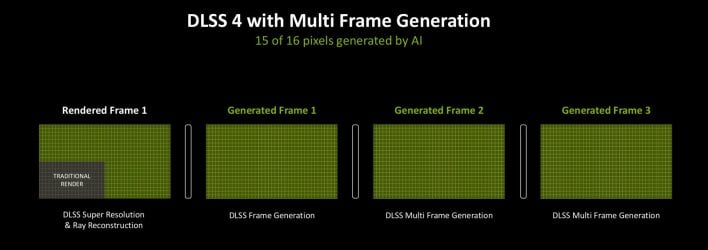
Observe that solely multi body era is unique to the RTX 50 sequence. All different DLSS options might be enhanced by way of the transformer mannequin, so previous-gen RTX playing cards will reap the advantages as properly, with the options they help.
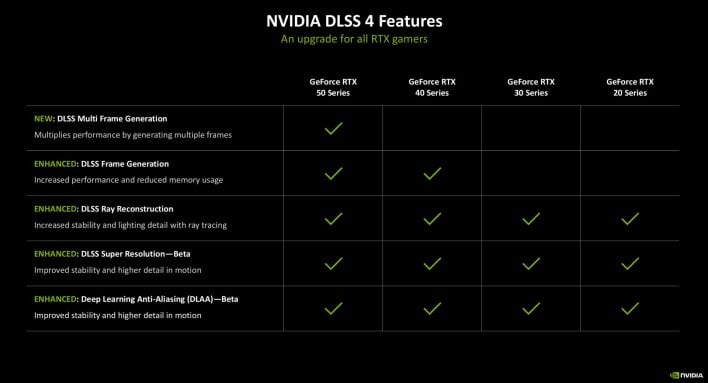
We must also point out that NVIDIA is introducing new DLSS override performance inside the NVIDIA app ass properly. DLSS overrides will give customers the flexibility to enabled DLSS multi body era in 75 DLSS FG titles, check out the most recent transformer fashions in DLSS SR titles, and override DLAA and Extremely Efficiency modes for DLSS SR titles (even in video games that don’t present a UI toggle for manipulating these options).
NVIDIA Reflex 2 To Additional Scale back Latency With Body Warping
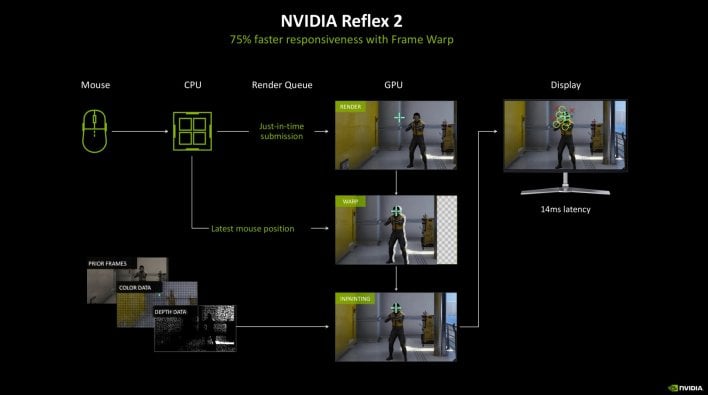
One of many points with body era is the potential impression on recreation responsiveness, as a result of consumer enter did not impact the generated body. To additional improve responsiveness in video games, NVIDIA can also be introducing Reflex 2. Reflex takes the entire goodness of Reflex and incorporates help for body warp. Body warping, nonetheless, could reveal holes within the information – for instance, what’s behind a pillar or wall. To deal with that challenge, NVIDIA can also be introducing inpainting predictive rendering to fill in these components of the scene. This may not be a win for each recreation, however it’s a good choice for video games the place somebody desires optimum latency. With Reflex 2, NVIDIA is claiming as much as 75% quicker responsiveness. Reflex 2 is coming to The Finals and Valorant quickly, and can come to extra titles at later dates.
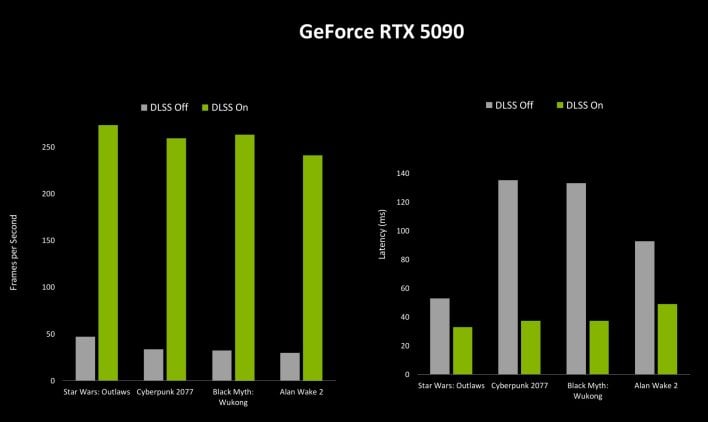
So, what does all of this AI and expertise do for framerates and latency? Properly, it leads to considerably decreased latency and as much as 8x increased framerates versus native rendering.
Let’s take a look at extra options and projected efficiency of NVIDIA’s GeForce RTX 50 Sequence, subsequent…
![[UPDATED 2.0] Phone mount and holder compatible with Samsung Z Fold 2 3 4 5 6 Pixel Fold or Foldable phone | bicycle, treadmill, handlebar, elliptical, stroller, rail, handle, roundbar, golf cart](https://m.media-amazon.com/images/I/51CjGlidGRL._SL1023_.jpg)








